レポートと論文の評価基準の違い
まえがき
論文とレポートの評価基準の違いについて、特にそれらの形式(外見)の違いの観点で説明する。 ここで論文とは卒論、修論、対外発表論文をすべて含んでいる。 もちろん博論もだが、博論を書こうというレベルの人にはこの記事は釈迦に説法なので読まなくてよい。
なおここで書いていることは私の経験や周囲の観測に基づいており、必ずしもそうではない場合ももちろんある。 特に研究分野が離れると文化が大きく違う可能性もある。
レポートは書きかけでも採点される
例えば問 1 から問 4 まで、ほぼ同じ難易度・分量の問題が 4 題あるレポート課題があるとする。 あなたは問 3 までは解けたが問 4 はサッパリ分からなかったので、問 3 までを完璧にして問 4 は白紙のレポートを提出した。 このとき、このレポートは何点ぐらいをもらえるだろうか?
もし私がこのレポートを採点するなら、各問について 25 点の配点を与え上記レポートは 25 点 x 3 = 75 点をつける。 おそらく多くの人がこれは妥当な判断だと考えるのではないだろうか? これはレポートの点数が、各問ができているかどうかによる加点方式(あるいは各問ができていないかによる満点からの減点方式)で採点されるためである。 レポートに限らず試験もこの方式で採点されるため、この方式に慣れていたりこの方式が当たり前と思っている人もいるのではないだろうか。
論文は書きかけでは採点されない
一方で論文は、書きかけでは採点されない(門前払いになる)場合が多い。 門前払いになるとは、途中にどんなに素晴らしいことが書いてあっても関係なく、 卒論や修論ならば不可になり卒業できない、査読付き論文であれば reject になるということである。
例えばあなたは修士研究で何か非常に本質的な問題を発見し、それを素晴らしい方法で解決したとしよう。 問題も解決策も素晴らしいのでそれだけでよい点をもらえるはずだと思い、 修論は書きかけ、例えば「関連研究」は章のタイトルだけ書いて中身は白紙、で提出したとする。
この修論は残念ながらおそらく多くの大学では不可になるだろう。 主査や審査委員会が寛容ならば「期日までに書き直し」になる可能性もあるが、一発で OK はありないと思う。 これは論文の採点が、全体として完成していることを前提としてスタートするからである。 完成していない論文は途中がよかろうが全体としては不可にせざるをえない。
つまりどうすればよいか
以上のことから逆算すると、論文で門前払いをくらわないためにはとにかく完成させることが重要であると言える。 例えば締切間際に、1. ある追加の実験をすること、2.「関連研究」の章を書ききること、の 2 つの TODO があるとする。 このとき優先すべきは明らかに 2 であり、追加実験が忙しくて論文が完成しなかった、という事態は絶対に避けるべきである(査読付き論文であれば「今回は諦めて、追加実験をして次の締め切りを目指す」こともありえるが、卒論や修論ではそうはいかない)。
W^X による保護により、古のとあるコードゴルフテクニックはそのままでは動かない
まえがき
与えられた入出力を満たすプログラムをなるべく短いバイト数で実現する遊びをショートコーディングまたはコードゴルフと呼ぶ。 後者の名前は、普通のゴルフがなるべく短い打数(stroke)でゴールを目指すことになぞらえてなるべく短いキータイプ(stroke)でプログラムを書くことを表現しているらしい。
C 言語でのコードゴルフで自分が非常に好きな(知った当時とても感銘を受けた)テクニックとして、「ソースコード中に直接バイナリを埋め込む」というものがある。 C のコードゴルフはルール上ソースコードをコンパイラにかけるのでバイナリを直接回答とすることはできないが、
- C 言語での関数呼び出しは単なるバイナリへのジャンプである
- C 言語では文字列リテラルは実行可能ファイルに直接バイナリとして埋め込まれる
ことを考える*1と、「文字列リテラルへのポインタを関数として呼び出す」ことが可能である。
このテクニックを利用して qsort 関数の呼び出しを短いバイト数で実現する方法がこのPDFの 5.3 に載っている*2。
この記事ではセキュリティのためのメモリ保護の影響でこのテクニックは残念ながら今の Linux ではそのままでは動作しないことを紹介する。
埋め込むバイナリの準備
まずセキュリティの前に x86 と x86_64 の関数呼び出し規約の違いにより、前述の PDF のコードはそのままでは動かない。 x86 では関数の引数はスタックに push して渡すことになっているが、 x86_64 では最初の 4 つの引数はレジスタで渡すことになっているためである。 そこで以下の C コードをまず x86_64 のマシン上で普通にコンパイルして出てきたバイナリを埋め込むことにする。
cmp(int*a,int*b){ return*a-*b; }
この関数を gcc -O3 でコンパイルすると、次のような非常に簡明なバイナリになる。
引数が rdi レジスタと rsi レジスタで渡されるので、それらの差を取って return している。
先頭の endbr64 も今回紹介するのとはまた別のセキュリティ機能だが、今は考えないことにする。
0: f3 0f 1e fa endbr64 4: 8b 07 mov (%rdi),%eax 6: 2b 06 sub (%rsi),%eax 8: c3 retq
バイナリを素直に埋め込む
出てきたバイナリを前述の PDF の 5.3 にあるように文字列としてプログラム中に埋め込むと、以下のようになる(#include ... は省略する)。
見やすさのために qsort の引数に直接文字列を渡さずにグローバル変数にしているが本質は変わらない。
char* s= "\xf3\xf\x1e\fa\x8b\a+\x6\xc3"; int main() { int array[] = {3, 1, 2}, size = 3; qsort(array, size, sizeof(int), s); printf("%d %d %d\n", array[0], array[1], array[2]); return 0; }
このソースコードをコンパイルして実行すると、残念ながら以下のように落ちてしまう。
$ gcc test.c (いろいろ警告が出るが関係ないので省略) $ ./a.out Segmentation fault (コアダンプ)
なぜ落ちるか?
前述のプログラムが Segmentation fault になる原因は、通称 W ^ X と呼ばれるセキュリティのためのメモリ保護である。 W ^ X とは、あるメモリページは書き込み可能(Writable)か実行可能(eXecutable)のどちらか一方のみに設定し、両方同時には設定しないようにするという方策のことで、英語の Wikipedia にも説明記事がある(残念ながら日本語はない)。 "^" という表記は xor の意味で、W か X かどちらかのみが 1 だというニュアンスである。
W ^ X は例えばスタック上のバッファにコードを送り込み実行させる攻撃の対策として有効である。
スタック上の値(array や size)はデータでありコードではない「はず」である。
よって読み書きをする可能性はあるが実行される可能性はなく、仮に実行されればそれは恐らく攻撃である。
そこでスタックを格納するメモリページはページテーブル上の管理ビットを writable かつ not executable に設定する。
当然 "\xf3 ... " のような文字列リテラルもデータでありコードではない「はず」なので、
それを格納するメモリページも not executable に設定される(文字列リテラルの場合は書き込みもできない点がスタックとは異なる)。
今回は実行できないメモリページにあるものを無理やり実行しようとしたので Segmentation fault が起きた。
読み書き可能かつ実行可能にすれば動く
呼び出したいバイナリが置かれたメモリページが実行不可能なのが悪いので、「読み書き可能」かつ「実行可能」なメモリ領域を作りそこにバイナリを置けば想定通り動く。
このようなメモリ領域は mmap 関数の第 3 引数に PROT_EXEC と PROT_READ と PROT_WRITE を同時に指定することで確保できる。
前から順に、確保するメモリ領域が実行可能であること、読み込み可能であること、書き込み可能であることを示す。
以上を踏まえ、結局次のようなコードであれば期待通りの動作をする(#include ... は省略する)。
code が実行可能かつ読み書き可能なメモリ領域で、埋め込みたいバイナリをその領域にコピーしてから呼び出している。
mmap の呼び出しがかなり長いので、残念ながらコードゴルフに使うのは難しそうである。
NULL や PROT_EXEC などをベタ書きしても void*c=mmap(0,99,7,34,0,0); とかなり長い。
unsigned char* s= "\xf3\xf\x1e\fa\x8b\a+\x6\xc3"; int main() { int array[] = {3, 1, 2}, size = 3; void* code = mmap(NULL, 4096, PROT_EXEC | PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, 0, 0); memcpy(code, s, strlen(s)); qsort(array, size, sizeof(int), code); printf("%d %d %d\n", array[0], array[1], array[2]); return 0; }
このコードをコンパイルし実行すると、以下のように見事 array の中身が整列される。
$ gcc test.c $ ./a.out 1 2 3
空撮の壁
まえがき
壁 Advent Calendar 2021 の22日目です(埋まっていた枠を空けてくれたあざら氏に感謝)。 今日はドローンで空撮して遊んでみた話を書きたいと思います。
機種選択の壁
まずはドローンを買わないといけませんが、そこでぶつかるのが機種選択の壁です。 ドローンはいまや一大産業(?)なので様々な企業から様々な機種が出ているようです。
機種選択にあたり重要になるのが規制の壁です。 自分が修士学生だったころは特に規制もなくみんな好き放題にしていたと思いますが、 最近ではドローンの数や事故が増えて規制が厳しくなっているようです。
国土交通省のルールによると、200 g 以上の機種には以下のような様々な規制があります。
人口密集地区の定義がよくわかりませんが(調べてない)、おそらく東京の住宅地では無理でしょうし建物の中で飛ばすのも 2 つ目のルールから無理です。 そこで初心者がドローンを買う場合には 200 g の壁を越えないものを選ぶことになります。 200 g を越えなければ「無人航空機」にあたらないただのおもちゃという扱いになるようです。
いろいろ調べたり価格.com を見たりした結果、DJI 社の MAVIC MINI という機種を購入しました。 初心者なので細かい違いは説明できないのですが、初心者が空撮をしたい場合はとりあえずこれを買っておけという機種のようです。 重量は日本仕様では 199 g に抑えられています(その代わりバッテリー容量が減らされている)。
 購入したドローン
購入したドローン
 収納のために羽の支えを畳んだ様子
収納のために羽の支えを畳んだ様子
 飛んでいる様子
飛んでいる様子
空撮場所の壁
購入したら次はどこで飛ばすかが問題になります。 200 g の壁を越えないものを購入したので室内で飛ばしてもいいのですが、今回したいのは空撮です。 東京の上空から空撮するのは法律上よくても別なところから文句を言われそうなので難しいです。
そこで今回はとあるど田舎にある祖父母宅で飛ばすことにしました。 どれくらい田舎かというと、隣の家は数十メートルも先、最寄りのお店は車で制限速度いっぱいで走って15分かかるようなところです。 (なので実は 200 g の壁を越えてもよかったのですが、初心者向けのものはそもそも越えないものしか売っていません。)
以下が空撮した写真です。素人なので飛ばすだけで精一杯 & 楽しくてあまりいい感じの写真は撮れませんでした。
 田舎です
田舎です
 田んぼです
田んぼです
 溜池です
溜池です
さらなる規制の壁
「機種選択の壁」で 200 g 未満であればめんどくさい規制を受けないと書きましたが、 実は来年からより厳しい規制の壁が登場してしまうことになりました。
2022 年の 6 月 20 日から、100 g 以上のドローンは登録しないと飛ばせない、 しかも登録は有料という初心者が思いつきではじめるにはかなりめんどくさいことになるようです。 詳しくはこちらに記載されています。
政治の壁
ちなみに今回購入したドローンの製造元である DJI 社ですが、 購入した数日後にアメリカの投資禁止リストに入れられてしまいました。
本機種の操作にはスマートフォンとコントローラーを接続する必要があるのですが、 もしかしたら今後アプリが公式ストアから ban されるというようなことが起こってしまうかもしれません。
終わりに:購入の壁
今回無事に計画通り空撮を楽しみ、壁カレンダーに参加することができました。 ドローンは通販で購入したのですが、実は最初は秋葉原のヨドバシあたりで買おうと思っていました(店頭のほうがオススメ等を聞けるので)。 しかし週末にヨドバシに向けて移動しはじめたところ、昼食を取ったところで疲れてしまいまぁいいやと家に帰ってしまいました。 もしそのまま購入に至らなかった場合には今回は購入の壁を越えられませんでしたというネタで誤魔化そうと思っていました。
TP-LINK Archer T4E AC1200 が Linux で何もせずに使えた話
前置きと買ったもの
自宅の床を這っているケーブルを減らしたくなり、デスクトップ PC を wifi 化することにした。
購入したのは TP-LINK の Archer T4E AC1200 というもので、通販で送料込みで約 3400 円だった。外箱は英語のみで通販サイトでも「法人向け」とか書いているが、中のマニュアルには日本語も書かれていた。

後付けの wifi モジュールには PCI Express スロットに刺すタイプ、USB で接続するタイプ、それからノート PC で使われている M.2 スロットに刺すタイプ(こういうやつ)があり、本機は PCI Express スロットに刺すタイプである。USB や M.2 でも動作すればなんでもよかったのだが、本機は事前に Linux で動きそうという確証があったのでこれにした。
事前に Linux で動きそうという確証はあったものの実際に動いた or 動かしているという報告は検索した限り見つからなかったので、ここにメモしておく。
Linux での動作
Linux での動作だが、単に接続しただけで本当に何もせずに使えた。具体的にいうと、接続して起動するとデスクトップ環境のネットワークマネージャ的なものに表示され、クリックして SSID を選んでパスフレーズを入れただけである。
これだけでは何なのでもう少し突っ込んだ情報を記しておく。まず本機に使われている wifi チップは Realtek の RTL8812AE というものである。これは lspci でも以下のように確認できるし、公式のフォーラム(注1)やこのページにも同様の情報がある。ただし今後チップが変わらない保証はないので注意が必要である。
注1:余談だが公式のフォーラムで「Ubuntu で動きますか」と聞いて「動くと宣伝はされてないけどチップ名はこれだよ」と教えてくれるのは偉い。日本のメーカーならサポートされてませんの一点張りで終わりそうだ。
... 03:00.0 Network controller: Realtek Semiconductor Co., Ltd. RTL8812AE 802.11ac PCIe Wireless Network Adapter (rev 01) ...
RTL8812AE は Linux では rtl8821ae というドライバでサポートされている。チップ名とドライバ名が微妙に違う(8812 と 8821)が、これで正しいようである。正確にはこのドライバは RTL8812AE と RTL8821AE の両方をサポートするようだ。lspci -v を見てみると実際にこのドライバが使われているのがわかる。
...
03:00.0 Network controller: Realtek Semiconductor Co., Ltd. RTL8812AE 802.11ac PCIe Wireless Network Adapter (rev 01)
Subsystem: Realtek Semiconductor Co., Ltd. RTL8812AE 802.11ac PCIe Wireless Network Adapter
Flags: bus master, fast devsel, latency 0, IRQ 148
I/O ports at e000 [size=256]
Memory at df100000 (64-bit, non-prefetchable) [size=16K]
Capabilities: <access denied>
Kernel driver in use: rtl8821ae
Kernel modules: rtl8821ae
...
rtl8821ae ドライバはカーネルのメインツリーに取り込まれており、CONFIG_RTL8821AE という設定でビルドするかどうか決められる。自分の使っているカーネルコンフィグ(Debian のどこかの時点のをコピーしてきて最新のカーネルに合うように make oldconfig したもの)では最初から m(モジュールとしてビルド)になっていた。
$ grep CONFIG_RTL8821AE /boot/config-`uname -r` CONFIG_RTL8821AE=m
ということで、チップ名が分かりそれが公式にサポートされていると知ったので事前にほぼ動くだろうと確証があった、という話だった。
Using Logitech (Logicool) Spotlight Remote in Linux
In two words: it works
Preface
I recently bought a Logitech Spotlight Remote with my own expense for my external lecturer work in an university outside of my home one. It costed me around 9,400 JPY (86 USD as of today). This seems to be much less expensive than the retail price on their US website (129.99 USD as of today), but I don't know why (I didn't buy it from a random Amazon seller but I got it from a "legit" electronics store).


For those of you don't know, the box says "Logicool" and not "Logitech", but it is completely genuine. The fact is that there already existed a company named Logitech (and it still does) before the Swiss Logitech started doing business in Japan, so they invented a new name "Logicool" only for use in Japan.
It works perfectly as advertised in my Windows machine, which I use for the lectures. It gives me an illusion like I am using an actual laser pointer pointing to the screen, not the computer. It also fits my need of doing "hybrid" lectures (a part of the students listen offline and others are on Zoom) because it shows a bold and red pointer at where I point (after installing their proprietary software) and the pointer is also visible on screen shared via Zoom.
Using it in Linux
OK, of course it works in Windows, but what about in Linux? As far as I tested, it works in Linux to an extent it is actually useful if not perfectly (the proprietary software doesn't work without a question though).
The forward and backward buttons: It seems that what they do is just sending "right arrow" and "left arrow" keystrokes. So, you can go forward and backward on your presentation using any software that use right and left arrows to move between slides. Examples include LibreOffice Impress, Evince, and Atril.
The "focus" button (the one on the top): How it works seems to be as follows. When you short-click it, it sends a "left click" keystroke and you can click anywhere on the screen with it. For example you can do something like clicking an embedded video on your presentation to start playing it. When you hold it, it starts working as a mouse and you can move the cursor. So even though the proprietary software to show the red and bold pointer doesn't work in Linux, you can still point where you focus in the slide using the mouse cursor, or maybe you can use some other software to make the mouse cursor bigger when it moves quickly.
The paring mechanisms: I couldn't try the Bluetooth paring mechanism as my Linux machine doesn't have a Bluetooth module. The USB paring dongle (which also uses Bluetooth I guess?) just works on Linux without doing anything other than inserting it to a USB port. The below is how the dongle shows up in lsusb (it says "Logitech" instead of "Logicool").
$ lsusb ... Bus 001 Device 009: ID 046d:c53e Logitech, Inc. USB Receiver
As you may have already noticed at this point, Logitech Spotlight Remote seems to be just a normal wireless mouse in its core, and it works fine with Linux as well. Please do not take me wrong as I think it still is a cool and useful device because of its mechanism to find where the user is pointing right now. You really feel like you are pointing the screen and there is no external sensor or manual calibration or whatsoever is needed.
USB Type-C の Linux での扱い
前回の記事で PCIe に刺すタイプの USB Type-C 拡張ボード(玄人志向 USB3.2C-P2-PCIE3)が Linux でいまいちうまく動かないということを書いた。 具体的にはデータ転送はうまくいっているようだが電源周りが怪しかったので、そのあたりを解決すべくいろいろ調べた結果をメモしておく。 なお残念ながら完璧に動かして 3 A を流すには至っていない。
前回の記事の冒頭で USB PD (Power Delivery) なしであっても Type-C の方が Type-A より流せる電流が大きいらしいと書いたが、これは USB Type-C Connector System Software Interface (UCSI) というもので定められている。 Intel の仕様によると、UCSI に SET_POWER_LEVEL というコマンドがあり USB Type-C Current というフィールドを 1 に設定すると 3 A、2 に設定すると 1.5 A となるようだ(引用: 56 ページの Table 4-48)。
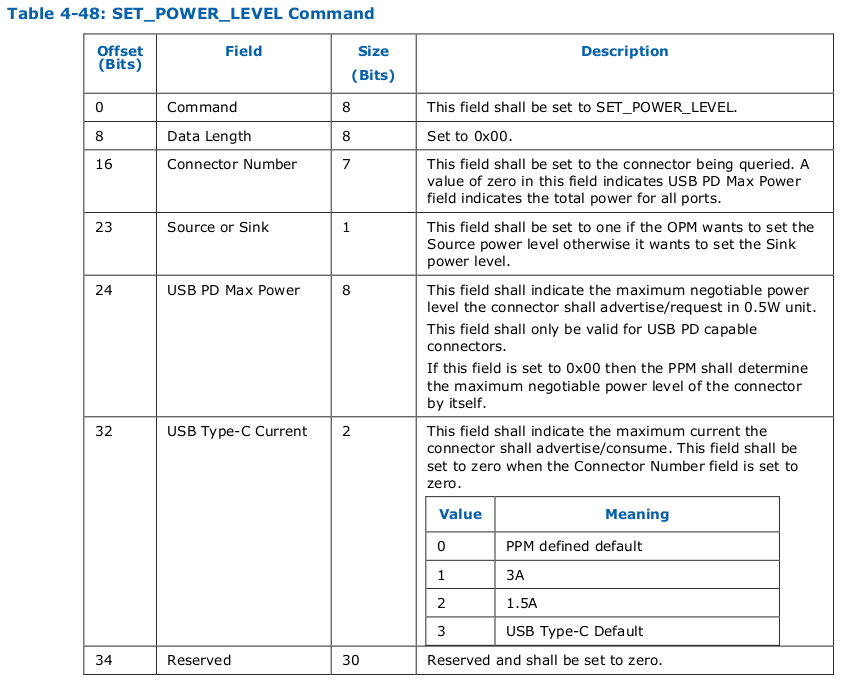
Linux では UCSI 関連のドライバは drivers/usb/typec/ucsi にあり、ucsi.h にある以下の定数定義が 3 A のモード等を表すと思われる(前述の仕様にある値と違いかつ仕様より値の種類が多いのが気持ち悪いが...)。
#define UCSI_CONSTAT_PWR_OPMODE(_f_) ((_f_) & GENMASK(2, 0)) #define UCSI_CONSTAT_PWR_OPMODE_NONE 0 #define UCSI_CONSTAT_PWR_OPMODE_DEFAULT 1 #define UCSI_CONSTAT_PWR_OPMODE_BC 2 #define UCSI_CONSTAT_PWR_OPMODE_PD 3 #define UCSI_CONSTAT_PWR_OPMODE_TYPEC1_5 4 #define UCSI_CONSTAT_PWR_OPMODE_TYPEC3_0 5
つまり Type-C で 3 A や 1.5 A を流すためにはここにある typec_ucsi のようなドライバを使わなければならないが、現状ではこのボードに対して xhci_pci しか使われている様子がない(なおカーネルの設定で CONFIG_TYPEC は y、 CONFIG_TYPEC_UCSI は m にしている)。 前回の記事で動いているケースでも電流が少ないと書いているが、その原因はたぶんここにある気がする。
ここからはかなり推測だが、おそらく PCIe に刺さったボード自体には xhci_pci ドライバを使い、さらにそこに生えている Type-C ポートを独立のデバイスとして認識し各ポートに typec_ucsi ドライバを使うのが正しい動作ではないだろうか。 カーネルの Type-C に関するドキュメントには "Every port will be presented as its own device under /sys/class/typec/"、"port drivers will describe every Type-C port they control ..." とあるのでポートごとにデバイスドライバが必要という認識で正しそうだ。
本ボードの動作に話を戻すと、なんとなく動いてはいるが /sys/class/typec/ には何も存在しない、つまり Type-C のポートが独立したデバイスとして認識されていない。
実は ASM3142 チップは Type-C と Type-A のどちらも扱えるようになっていて、例えば同じ玄人志向からは ASM3142 搭載で Type-A ポートを増設するボードも売られている。
このあたりが Type-C ポートが独立したデバイスとして認識されず typec_ucsi ドライバも使われていないことの原因になっている気はする。
さらに言うと、Type-C がいろいろな機能を持ちすぎていてポートやケーブル自体をデバイスドライバで制御しないといけないことが遠因と言えそうだ。 元々 USB ポート・ケーブルは電気的に決まった動作をするただの結線であり、ソフトウェアからは意識する必要がなかったはずである。 例えば Type-A ポートを制御する PCI ボードがあればソフトウェアはそのボードさえ制御していればよく、ボードについている Type-A ポートはボードに載ったコントローラチップがよろしくやっておいてくれればよい。 しかし Type-C で流す電流・電圧を変えるとかどちらがソース・シンクか動的に変わるとかを実現せねばならないため、意識しなくてよい単なる物理層であったポートをソフトウェアから制御する必要が出てきた(つまりある抽象化レイヤにあったものが高機能化のために一つ上のレイヤに移動してしまった)、 その結果今回のような不一致が出てくる原因になった、と考えている。
ASMedia ASM 3142 と OPPO Reno3 A の相性問題?
あらすじ
- PC にスマホを繋いでいる時の充電が遅いので 5V 3A が流せると謳う PCIe USB-C 拡張ボードを購入
- Linux マシンに装着し OPPO Reno3 A を繋いでみたがうまく動かない
- どうやら相性問題っぽい??
買ったもの
購入したのは玄人志向の USB3.2C-P2-PCIE3 というボード。 PC への接続は PCIe v3 x4(以上)で、USB 3.2 Gen2 の Type C ポートが 2 個ついている。 1 ポートのみ使用のときは最大で 5V 3A、2 ポート同時に使用した時は 5V 4A まで流せるらしい。 ただし USB PD (Power Delivery) には対応していない。 USB PD 非対応で 5V 3A 程度ならわざわざボードを買うほどなのか?という気もするが、ここによると Type A だと 5V 1.5A までしか流せないらしく、今は PC の Type A ポートに接続しているので意味があると思った。



ボードの外観と接続した様子。SATA の電源ケーブルから補助電源を取る仕組みになっている。ただ最大 5V x 4A == 20 W に対し PCIe x4 で供給できる電力は 25 W らしいので補助電源がいるのかは謎である。
なおこのボードは玄人志向が販売しているが実際はどこかの OEM なのか、この StarTech のボードと全く同じである。値段は玄人志向の方がかなり安い。 なお玄人志向のページには USB 3.2 Gen 2 とあり StarTech のページには USB 3.1 Gen 2 とあるが、これらは同じものらしい。 また BEYIMEI というベンダーのこのボードは周辺回路の配置が微妙に違うが使われているチップ(ASMedia ASM 3142)や SATA の電源をつなぐあたりが同じなので機能的にはほぼ同じものと思われる。
Linux での動作
本ボードのメインチップは ASMedia の ASM 3142 である。 玄人志向のページでは対応 OS 欄に Windows しか書いていないが、 まったく同じボードだと思われる StarTech のページでは Linux 対応が謳われている。 またASMedia のページでも Linux に対応していると書いてあるので、Linux でも問題なく動くだろうと判断した。
実際に接続してみると、このページにあるように ASM 3142 ではなく ASM 2142 として認識された。 ドライバは専用のものではなく汎用の xhci_hcd というものが使われている。 カーネルの configuration 一覧(例えば make menuconfig)で ASM とか 2142 とかを検索しても何も出てこないので専用のドライバはない(不要?)ようである。
$ lspci -v
...
03:00.0 USB controller: ASMedia Technology Inc. ASM2142 USB 3.1 Host Controller (prog-if 30 [XHCI])
Subsystem: ASMedia Technology Inc. ASM2142 USB 3.1 Host Controller
Flags: bus master, fast devsel, latency 0, IRQ 16
Memory at df200000 (64-bit, non-prefetchable) [size=32K]
Capabilities: <access denied>
Kernel driver in use: xhci_hcd
Kernel modules: xhci_pci
...
2021/01/06 追記:xhci ドライバのコードは明示的に ASM 2142 と ASM 3142 を同じものだと思って書かれている。つまり 2142 として認識されるのは全く想定通りの動作である。このコミットログに "The ASM2142/ASM3142 (same PCI IDs) ..." とあり、ASM 2142 と ASM 3142 向けの修正が pdev->device == 0x2142 という条件のみで書かれている。
相性問題?
PC に接続ができたので早速 OPPO Reno3 A を Anker の PowerLine III 経由でつないでみたところ、充電されないどころかスマホ側で PC に接続されたことを認識しない(認識されればスマホ側に PC とデータ転送するかどうかをたずねる通知が出るはずだが、それがでない)。しかし逆に PC 側ではスマホが接続されたことをきちんと認識しており、dmesg や lsusb にはちゃんと OPPO の機器が繋がっていることが表示される。手元にあった別の Type C - Type C ケーブルで繋いでみても全く同じ結果だった。
$ sudo dmesg ... [60965.205189] usb 5-1: new high-speed USB device number 14 using xhci_hcd [60965.437758] usb 5-1: New USB device found, idVendor=22d9, idProduct=2764, bcdDevice= 4.14 [60965.437761] usb 5-1: New USB device strings: Mfr=1, Product=2, SerialNumber=3 [60965.437762] usb 5-1: Product: SM6125-IDP _SN:895ABEB8 [60965.437763] usb 5-1: Manufacturer: OPPO [60965.437764] usb 5-1: SerialNumber: 895abeb8
$ lsusb ... Bus 005 Device 014: ID 22d9:2764 OPPO Electronics Corp. SM6125-IDP _SN:895ABEB8 ...
ボード自体がちゃんと動いていることを確認するために、(1) Type C - Type A アダプタ + USB メモリ と (2) Type C - Type C ケーブル + タブレット を接続してみたところ、(1) ではちゃんとデータ転送ができ、(2) ではちゃんと充電されかつタブレット側で PC に接続されたことを認識した。 ただし (2) の充電はかなり遅く、明らかに 3A も流れていないと思われる。 さらに不可解なことに、Type C - Type A アダプタ経由で OPPO Reno3 A を接続すると充電もスマホ側で認識もされるという結果になった。
まとめると以下のような状態である。
| 機器 | 接続方法 | 結果 |
|---|---|---|
| OPPO Reno 3A | Type C - Type C ケーブル | 充電せず、スマホ側で PC を認識せず、PC 側ではスマホを認識 |
| USB メモリ | Type C - Type A アダプタ | 問題なし |
| タブレット | Type C - Type C ケーブル | 充電、タブレット側での PC 認識ともにするが、充電は遅い |
| OPPO Reno3 A | Type C - Type A アダプタ + Type A - Type C ケーブル | 充電、スマホ側での PC 認識ともにするが、充電は遅い |
これ以上のことは現状よく分からないが、どうも OPPO Reno3 A は相性問題が起きやすい?らしく、こちらのブログにいろいろまとまっている。 その記事に「本来は、USB PDにしろQuick Chargeにしろ、最初はUSB標準の給電動作をした上で、機器間の通信で対応を確認して設定を変更する手順を踏みますから、全く給電されないということは起こらないはず」とあるように、 たとえお互いに対応した仕様がない場合でも一番 basic なUSB給電としては動くはずなので、今回の結果はかなりおかしな状態と思われる。 ボードからの電力がそもそも足りていないのであればまだ分かるが、Type C - Type A アダプタをかませるとちゃんと動くのも謎である。https://www.kernel.org/doc/html/v5.10/driver-api/usb/typec.html